
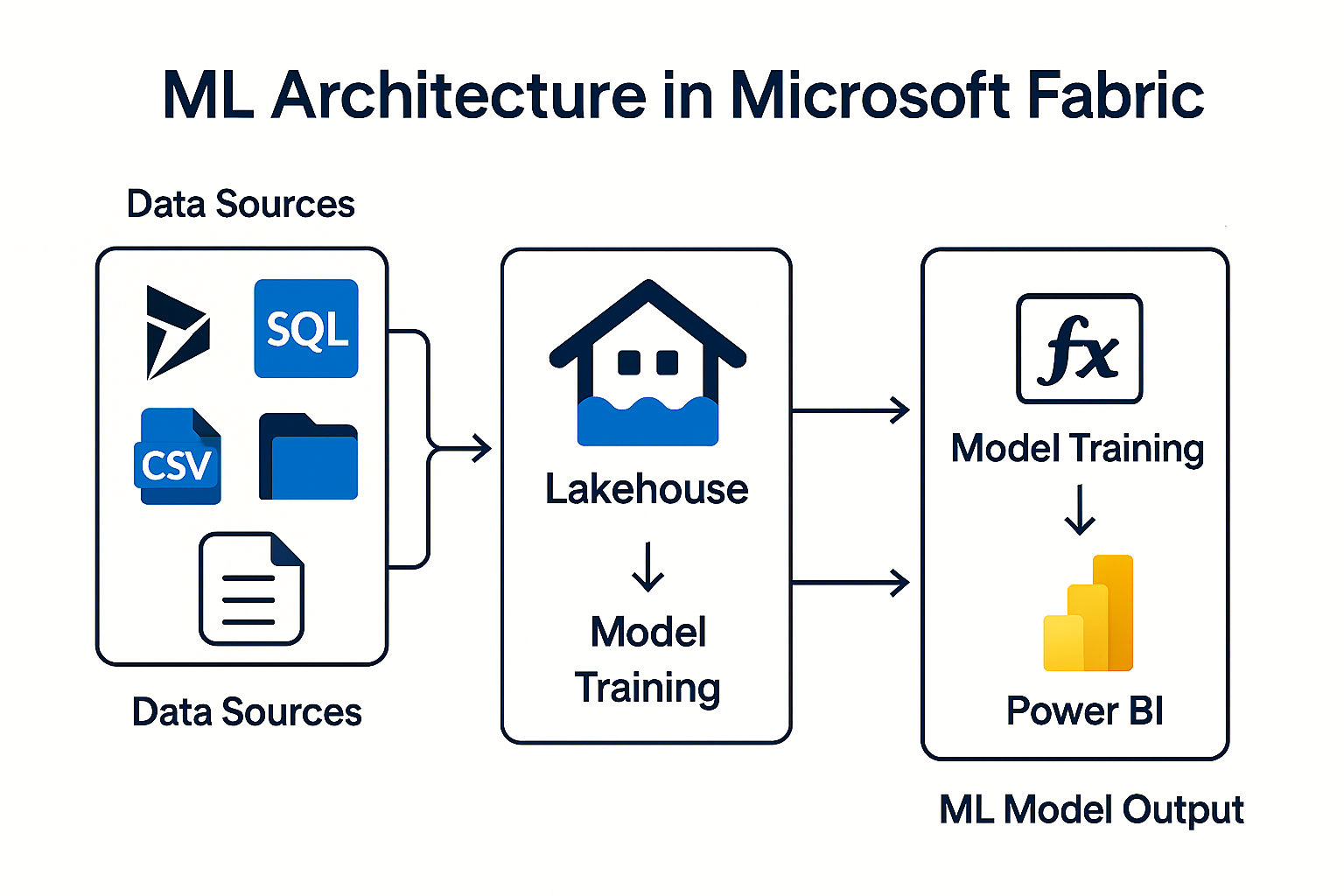
Microsoft Fabric schafft eine einheitliche Plattform für Datenintegration, Analyse, Data Engineering und Data Science. Ein herausragender Baustein darin: Machine Learning (ML) – nahtlos integriert, voll orchestrierbar und ideal geeignet, um Daten aus Microsoft Dynamics NAV, Navision und Business Central intelligent auszuwerten.
Intern setzen eure Projekte ML‑Modelle z. B. für Churn‑Prevention, Forecasting, Scoring Pipelines und Automatisierungen ein. ML‑Modelle werden über Notebooks, Pipelines oder AutoML erzeugt und über MLflow verwaltet.
Auch in der Projektübergabe werden ML‑Modelle als zentraler Bestandteil der Fabric‑Architektur genannt.
Was ist ein ML‑Modell in Microsoft Fabric?
Ein ML‑Modell ist eine trainierte mathematische Struktur, die Muster in Daten erkennt und Vorhersagen trifft – z. B.:
- Abwanderungswahrscheinlichkeit eines Kunden in Navision/NAV
- Zahlungswahrscheinlichkeit oder Kreditlimit in Business Central
- Artikel‑Bedarfsprognosen aus BC‑Sales Ledger
- Lead‑Qualität oder Kampagnenverhalten
Fabric integriert diese Modelle als erstklassige Artefakte in der Data‑Science‑Experience:
- sie laufen in Notebooks,
- werden von Pipelines gesteuert,
- speichern ihre Ergebnisse im Lakehouse,
- werden über MLflow überwacht und versioniert.
Wie funktioniert ML in Fabric technisch?
1. Datenvorbereitung in Lakehouse oder Warehouse
Datenquellen können dabei sein:
- BC‑Daten (OData, API, Mirroring)
- NAV‑Exporte (CSV, Excel)
- Navision Altsysteme
- Dataverse‑Daten
2. Modelltraining – Notebook oder AutoML
Fabric bietet zwei Wege:
a) Modelltraining per Notebook
Notebooks enthalten Python- oder PySpark‑Code und können:
- Features erstellen
- Modelle trainieren
- Modelle speichern
- Scoring nach Laden neuer Daten durchführen
Diese orchestrierte Kombination wird in mehreren deiner Dateien beschrieben:
Ein Notebook kann direkt nach einem Pipeline‑Load ausgeführt werden und anschließend Predictions in das Lakehouse schreiben.
b) AutoML – Modell per Klick erstellen
Die interne Dokumentation zeigt, dass AutoML:
- einen Assistenten mit 6 Schritten bietet (Datenquelle, Datenwahl, Modellzweck, Trainingsdaten, Details, Review)
- automatisch ein vollständiges Notebook generiert
- FLAML („Fast Lightweight AutoML“) im Hintergrund verwendet
- Modelle & Metriken automatisch in MLflow speichert
Damit lassen sich ML‑Modelle ohne tiefes Data‑Science-Wissen aufsetzen.
3. Modellverwaltung – MLflow
Fabric nutzt MLflow, um:
- Modellversionen zu speichern
- Parameter & Hyperparameter zu dokumentieren
- Trainingsmetriken zu tracken
- Modelle reproduzierbar zu machen
Die interne Dokumentation bestätigt, dass AutoML Outputs und Modelle automatisch in MLflow speichert
4. Operationalisierung – Modelle produktiv nutzenML‑Modelle werden produktiv, indem sie in Pipelines eingebettet werden.
Übliche Abfolge:
- Pipeline lädt neue BC‑ oder NAV‑Daten
- Notebook führt Scoring durch (z. B. „Abwanderungsrisiko berechnen“)
- Ergebnis wird im Lakehouse gespeichert
- Power BI zeigt das Ergebnis im Dashboard
Die Data‑Science‑Architektur in deinen Unterlagen beschreibt genau dieses Muster.
5. Nutzung in Power BI
Nach dem Scoring landen Ergebnisse in:
- Lakehouse (Delta Tables)
- Warehouse (Tabellen)
Power BI kann diese Daten:
- direkt als Datasets anbinden
- in Reports als KPI, Prognose oder Segmentierung anzeigen
So entsteht ein echter Closed Loop zwischen ML und Business Intelligence.
Machine Learning in Microsoft Fabric ist:
- einfacher (AutoML, No‑Code‑Ansätze),
- skalierbarer (Spark‑Cluster, Pipelines),
- integrierter (OneLake + Power BI),
- und ideal für NAV, Navision & Business Central.
Egal ob es um Churn‑Modelle, Forecasting, Liquiditätsplanung oder Kampagnenoptimierung geht – Fabric liefert alles aus einer Hand:
Daten → Modell → Scoring → Reporting → Business Impact.
Do you have any questions or would you like to find out more about our methods? Get in touch with us - We show you how you can use your data for sustainable success.