
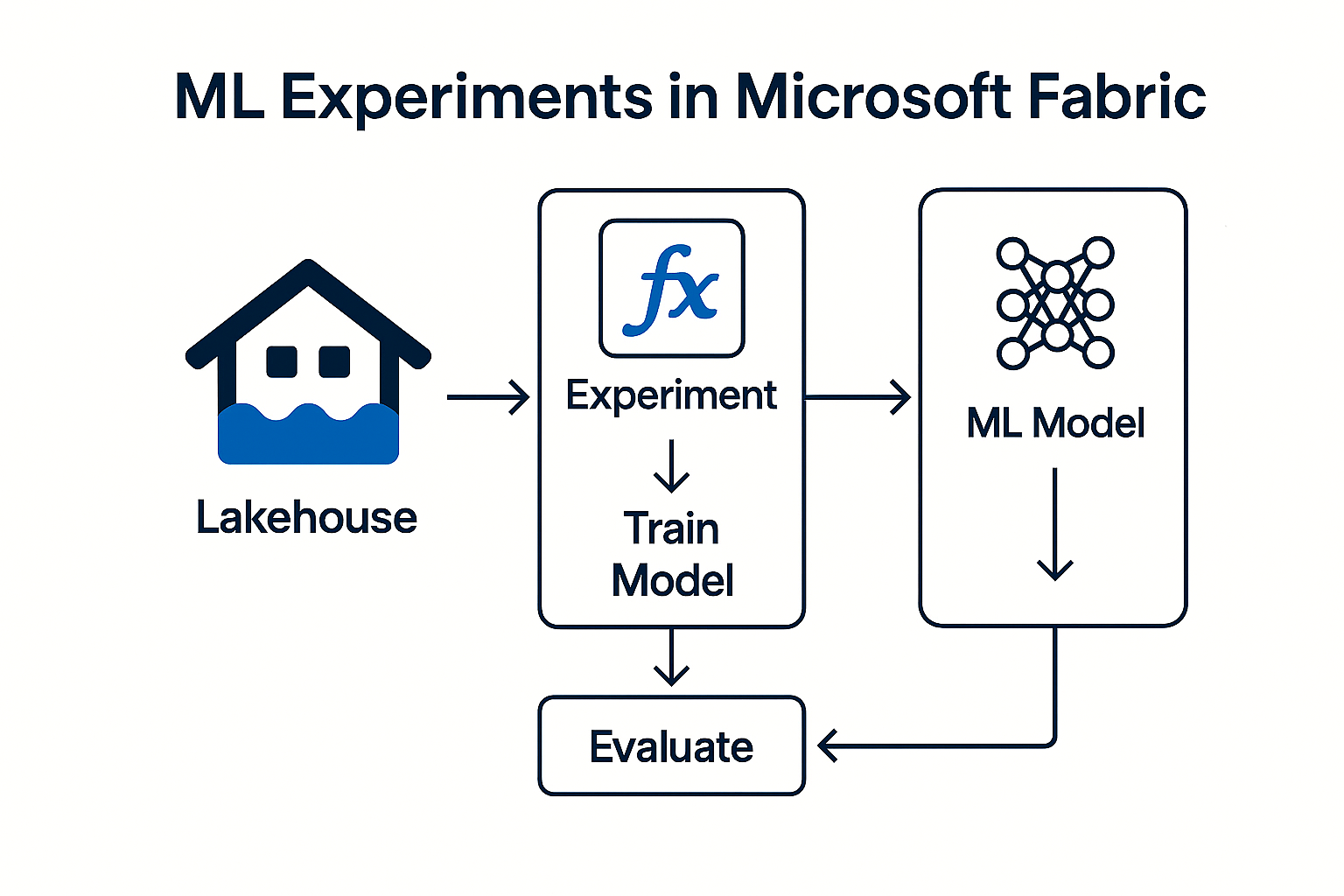
Machine learning (ML) is a central component of modern data analysis. In Microsoft Fabric there is a separate artifact for this: Experiments.
They serve as a systematic environment in which data scientists can compare, test, optimize and version ML models - including all training runs, errors, hyperparameters and performance metrics.
Especially when companies use data from Microsoft Dynamics NAV, Navision or Business Central, a clean, reproducible experimentation environment is crucial. Why is that?
Because BC/NAV data often contains complex patterns (e.g. in customer, article, financial or booking data) that require precise models for forecasting, churn risks or liquidity planning.
What is an experiment in Microsoft Fabric?
A Experiment is a structured collection of:
- different ML model versions
- Results of individual training runs
- KPIs such as Accuracy, R² or Loss
- Metadata such as
trial_timeor feature configurations
It therefore serves as a „laboratory“ for the entire training and optimization process.
The experiment process: train, test, repeat
Fabric describes the experiment workflow as a repeated cycle:
- Training - Model is adapted to training data
- Evaluation - Model performance is measured
- Testing - Validation on unknown data
- Iteration - Experiments are repeated until a satisfactory result is achieved
An experiment saves each of these iterations - perfect for reproducible data science work.
What is stored in an experiment?
The experiments contain:
- the model itself
- all model versions
- the results of each run
- important metrics such as R-Squared (R²)
- Runtime information such as trial_time
This allows data scientists to understand exactly which models work well and why.
What happens after the experiment?
When the optimal model has been determined:
- A Notebook retrieves the model stored in Fabric
- It generates regularly Predictions
- The predicted values are saved in a table in the Lakehouse
- Power BI uses this data directly for dashboards
This means that ML Fully operationalized - without external tools.
These systems provide extensive historical data ideal for forecasts, risk analyses or customer models. Seamless integration with Lakehouse, Notebooks and Pipelines - as also described in your internal project documents - means that experiments can be optimally operationalized and holistically integrated into your fabric architecture.
This makes Fabric a platform that not only trains ML models, but also makes them reliably usable in productive business processes. Companies that rely on BC/NAV data can thus accelerate data-based decisions, automate processes and integrate AI-supported insights directly into Power BI and operational workflows. Experiments are therefore a central key to fully exploiting the potential of machine learning in the Dynamics environment.
Do you have any questions or would you like to find out more about our methods? Get in touch with us - We show you how you can use your data for sustainable success.