
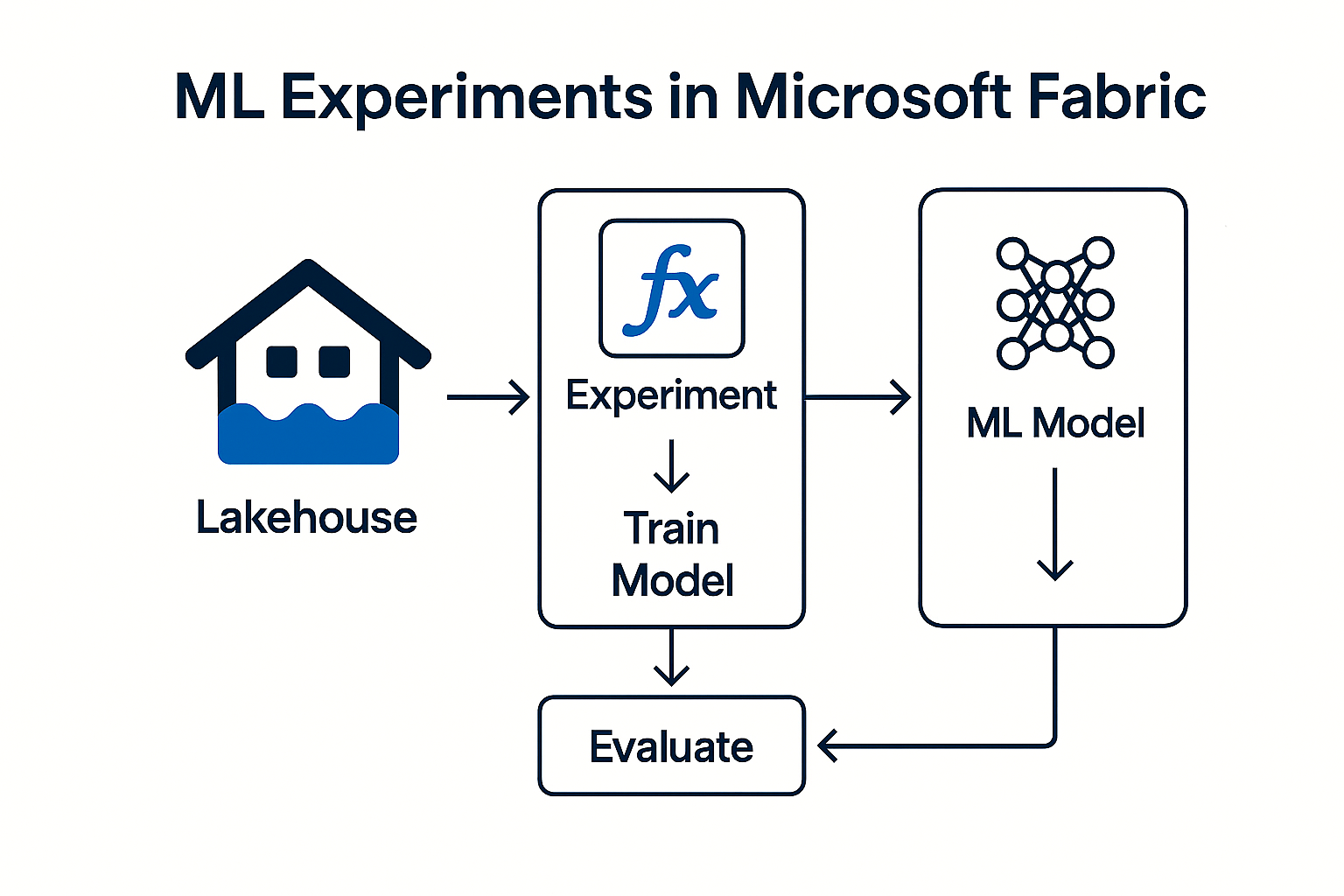
Machine Learning (ML) ist ein zentraler Bestandteil moderner Datenanalyse. In Microsoft Fabric gibt es dafür ein eigenes Artefakt: Experiments.
Sie dienen als systematische Umgebung, in der Data Scientists ML‑Modelle vergleichen, testen, optimieren und versionieren können – inklusive aller Trainingsläufe, Fehler, Hyperparameter und Leistungsmetriken.
Gerade wenn Unternehmen Daten aus Microsoft Dynamics NAV, Navision oder Business Central nutzen, ist eine saubere, reproduzierbare Experimentierumgebung entscheidend. Warum?
Weil BC/NAV-Daten oft komplexe Muster enthalten (z. B. in Kunden-, Artikel-, Finanz- oder Buchungsdaten), die präzise Modelle für Forecasting, Churn‑Risiken oder Liquiditätsplanung erfordern.
Was ist ein Experiment in Microsoft Fabric?
Ein Experiment ist eine strukturierte Sammlung von:
- verschiedenen ML‑Modellversionen
- Ergebnissen einzelner Trainingsläufe
- KPIs wie Accuracy, R² oder Loss
- Metadaten wie
trial_timeoder Feature‑Konfigurationen
Es dient somit als „Labor“ für den gesamten Trainings‑ und Optimierungsprozess.
Der Experiment‑Prozess: Trainieren, Testen, Wiederholen
Fabric beschreibt den Experiment‑Workflow als wiederholten Zyklus aus:
- Training – Modell wird auf Trainingsdaten angepasst
- Evaluation – Modellleistung wird gemessen
- Testing – Validierung auf unbekannten Daten
- Iteration – Experimente werden solange wiederholt, bis ein zufriedenstellendes Ergebnis erreicht wird
Ein Experiment speichert dabei jede dieser Iterationen – perfekt für nachvollziehbares Data‑Science‑Arbeiten.
Was wird in einem Experiment gespeichert?
Die Experiments enthalten:
- das Modell selbst
- alle Modellversionen
- die Ergebnisse jedes Laufs
- wichtige Metriken wie R‑Squared (R²)
- Laufzeitinformationen wie trial_time
Damit können Data Scientists genau nachvollziehen, welche Modelle gut funktionieren und warum.
Wie geht es nach dem Experiment weiter?
Wenn das optimale Modell festgelegt wurde:
- Ein Notebook ruft das in Fabric gespeicherte Modell ab
- Es generiert regelmäßig Vorhersagen
- Die vorhergesagten Werte werden in einer Tabelle im Lakehouse gespeichert
- Power BI nutzt diese Daten direkt für Dashboards
Damit wird ML vollständig operationalisiert – ohne externe Tools.
Diese Systeme liefern umfangreiche historische Daten ideal für Prognosen, Risikoanalysen oder Kundenmodelle. Durch die nahtlose Integration mit Lakehouse, Notebooks und Pipelines – wie auch in deinen internen Projektunterlagen beschrieben – lassen sich Experimente optimal operationalisieren und ganzheitlich in eure Fabric‑Architektur einbinden.
Damit wird Fabric zu einer Plattform, die nicht nur ML‑Modelle trainiert, sondern diese auch zuverlässig in produktiven Geschäftsprozessen nutzbar macht. Unternehmen, die auf BC/NAV‑Daten setzen, können so datengestützte Entscheidungen beschleunigen, Prozesse automatisieren und KI‑gestützte Insights direkt in Power BI und operative Workflows integrieren. Experiments sind damit ein zentraler Schlüssel, um die Potenziale von Machine Learning im Dynamics‑Umfeld vollständig auszuschöpfen.
Haben Sie noch Fragen oder möchten Sie mehr über unsere Methoden erfahren? Kontaktieren Sie uns – wir zeigen Ihnen, wie Sie Ihre Daten für nachhaltigen Erfolg nutzen können.